01 — what breaks
Standard reload mechanisms don't cover this.
Envoy hot restart, HAProxy expose-fd, NGINX SIGUSR2, Kubernetes preStop, HTTP/3 QUIC migration — every one of them is a cooperative-shutdown protocol. None survive an uncooperative crash with byte-perfect application state.
Expand →
Two dated incidents in 2026 make the shape visible.
Millions of users and API developers stare at "Error in message stream" and dropped generations. The culprit isn't a broken model — it's a breakdown in how long-lived HTTP / SSE streams survive backend infrastructure churn.
Minor control-plane blips trigger immediate client-retry loops, multiplying traffic into an aggressive upstream thundering herd that brings down the entire platform.
Every mechanism the industry standardized on for zero-downtime reload is cooperative: it depends on the process being replaced actively participating in the handoff. None of them survive SIGKILL, OOM-kill, or node loss — the events that actually dominate outage counts. None of them hand off byte-perfect application state across a process boundary. Most cover only one layer.
| Mechanism | What it covers | What it doesn't |
|---|---|---|
| Envoy hot restart | Parent–child fd handoff during cooperative reload | Uncooperative crash; no byte-perfect application state |
| HAProxy expose-fd / nbthread | Seamless reload, socket fd across processes | Crash, OOM-kill; no held application state |
| NGINX SIGUSR2 binary upgrade | Cooperative binary upgrade, worker recycling | Crash; no application state; single layer only |
| K8s preStop + terminationGracePeriodSeconds | Bounded grace window before SIGTERM | SIGKILL / OOM-kill / node loss bypass it entirely |
| HTTP/3 QUIC connection migration | Client IP change, network-path change | Process death; no application state; single layer only |
| Trevi | Cooperative reload and uncooperative crash. Byte-perfect application state across L4 / L7 proxy, WebSocket, compressed SSE, pgbouncer, Postgres session, and vLLM — in a single design. | — |
Backoff became our architecture. Trevi changes that assumption.
02 — what survives
What Trevi keeps alive, layer by layer.
One continuity property applied at every layer where the stream lives — measured, single-flow, shipping code. Every trial count below is from an Azure test bed against real vLLM.
Expand →
We didn't pick one layer and ship a point fix. We built the property at every layer where the stream lives — and measured it end to end.
SIGKILL. 6 / 6 trials, mean 1.56 s container-down, invisible to the client. Vanilla nginx: 0 / 6.SET parameters survive container SIGKILL. 50 / 50 trials, mean 209 ms container-down. Vanilla: 0 / 50 (session drops even when the socket comes back).SIGKILL: 50 / 50 byte-identical to the no-kill baseline, mean 28.32 s recovery, GPU pages reclaimed (no disk reload), zero missing tokens. Vanilla: 0 / 50.SIGKILL on the vLLM backend mid-SSE stream: 50 / 50 trials, mean 31.0 s end-to-end, single TCP, no application retry, no client reconnect.SET parameters at the pool layer · safe-boundary detector for compressed SSE · GPU-page reclaim, no disk reload · single TCP, no application-level retry. Sub-1% steady-state CPU overhead — kernel TCP state lives where it always did; the broker publish-diff runs on the crash path, not the hot path.
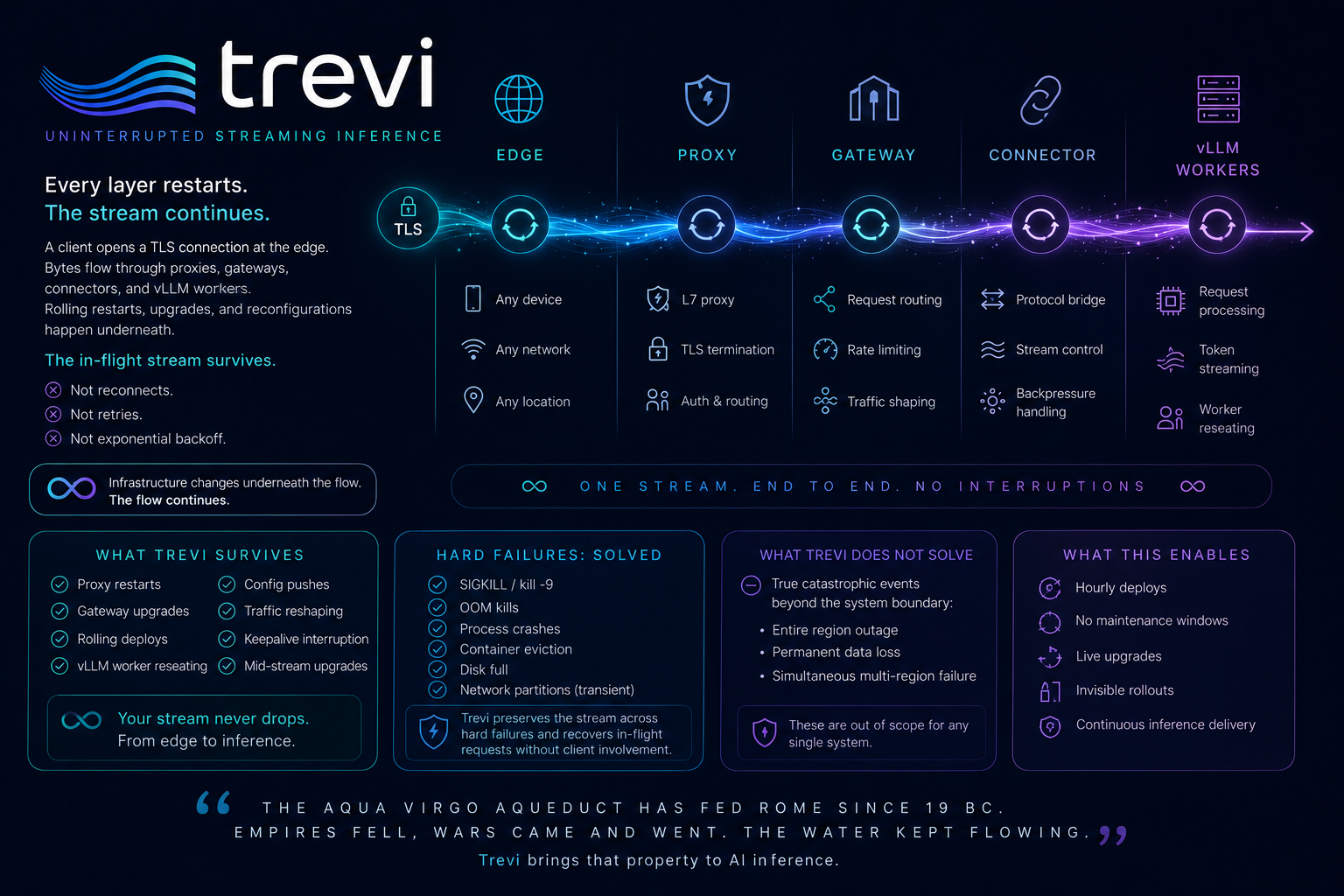
Same property. Every layer of your inference pipeline.
03 — what it costs
What today's fragility costs you.
Frontier inference on 1 000 × 8×H100 replicas: eight-figure recoverable annually, dominated by storm-absorption capacity buffer and velocity drag. The same pattern scales to $100B-class buildouts — and downshifts cleanly to 10M-connection SaaS.
Expand →
The per-event measurements above are real: Azure test bed, single TCP, shipping code. The dollar figures below translate those measurements into a representative production year — every assumption stated so the model is recalculable on your own numbers.
Assume ~104 disruptive events per stack per year, ~$30 / hour idle H100, Opus / Codex-class serving at ~$15 / M output tokens. Vanilla SIGKILL loses the request entirely (0 / 50) and forces 30–100 s of disk-reload retry; Trevi delivers in-flight bytes-perfect in mean 28.3 s, model-load 50–200× faster via GPU page reclaim.
Recoverable per stack, per year: ~$14M – $22M — dominated by capacity over-provisioning for storm absorption ($8M–$13M) and indirect productivity drag ($20M+ in a 20-engineer team's shipping cadence).
How the number decomposes
GPU idle during restart, ~$15k / year. Small on its own; matters because every idle H100-second is capacity the operator paid for and didn't ship a token for.
Token revenue forfeited, ~$72k → ~$44k / year. In-flight inferences resume on the same connection instead of being lost and regenerated.
Capacity over-provisioning for storm absorption, ~$8M–$13M / year. Production inference fleets keep dedicated H100 headroom specifically to absorb thundering herds during deploys. With Trevi the herds don't form and that buffer stops being load-bearing.
Operational, ~$13k–$38k / year at 2025 ML-engineer rates: $500k / year burdened comp × 13 storm-causing deploys × 2–4 hours × 2–3 engineers per response.
Productivity drag, ~$3M direct + $20M+ indirect / year. A 30% velocity drag on a 20-engineer $10M-payroll frontier-AI team. The indirect line dominates: visibly slower model rollouts, longer customer-acquisition cycles, faster-shipping competitors closing gaps the team had opened.
Orchestration to work around the failures, ~$3M–$5M / year. 5–10 engineers on SRE / infra / SDK teams doing nothing but retry layers, backoff schedules, idempotency-key stores, "did the client actually get the response" verification. Every line becomes deletable.
~50 routine deploys and ~50 unplanned crashes per year. At the DORA-medium change-failure rate, ~25% of deploys trigger a reconnect storm dropping 100k–500k connections; 1.3M–6.5M visible disruptions annually across the fleet.
Recoverable per year: ~$1.5M – $11M — brand and churn on user-visible disruptions, plus a 20-engineer team's feature lead time stretching 2–3× because deploys became scary.
How the number decomposes
Operational, ~$40k–$130k / year. 13 storm-causing deploys × 2–4 hours of on-call × 2–3 engineers, plus a 2–5× auto-scaling surge while the reconnect cliff drains.
Brand & revenue, $1M–$10M / year. 1.3M–6.5M visible disruptions per year on a 10M-user product. NPS drops empirically –5 to –10 points per percentage-point of reliability incidents; churn lift ~1% at $10 / user / month.
Productivity, $500k–$1M / year for a 20-engineer team. Deploys batch larger, push to off-hours, gate on extensive pre-deploy testing. Feature lead time stretches 2–3×. The hidden cost isn't the deploy — it's everything the team didn't ship because the deploy was scary.
The same math, rerun at the four scales that are actually being built in 2025–2027:
| Scale | H100s | Capex | Run / yr | Recoverable / yr |
|---|---|---|---|---|
| Base (what we modeled) | 8k | $0.24B | $0.26B | $34M – $41M |
| Mid frontier lab (~Anthropic 2024) | 50k | $1.5B | $1.64B | $120M – $154M |
| Large frontier lab (~xAI Colossus, Meta-2026) | 500k | $15B | $16.4B | $800M – $1.0B |
| $100B-class datacenter (Stargate-tier) | 2.5M | $75B+ | $82B | $3.5B – $4.3B |
At $100B-class scale the recoverable cost sits between $3.5B and $4.3B per year, dominated by capacity over-provisioning for storm absorption and indirect productivity drag.
Recoverable. Whether it is recovered is a rollout choice.